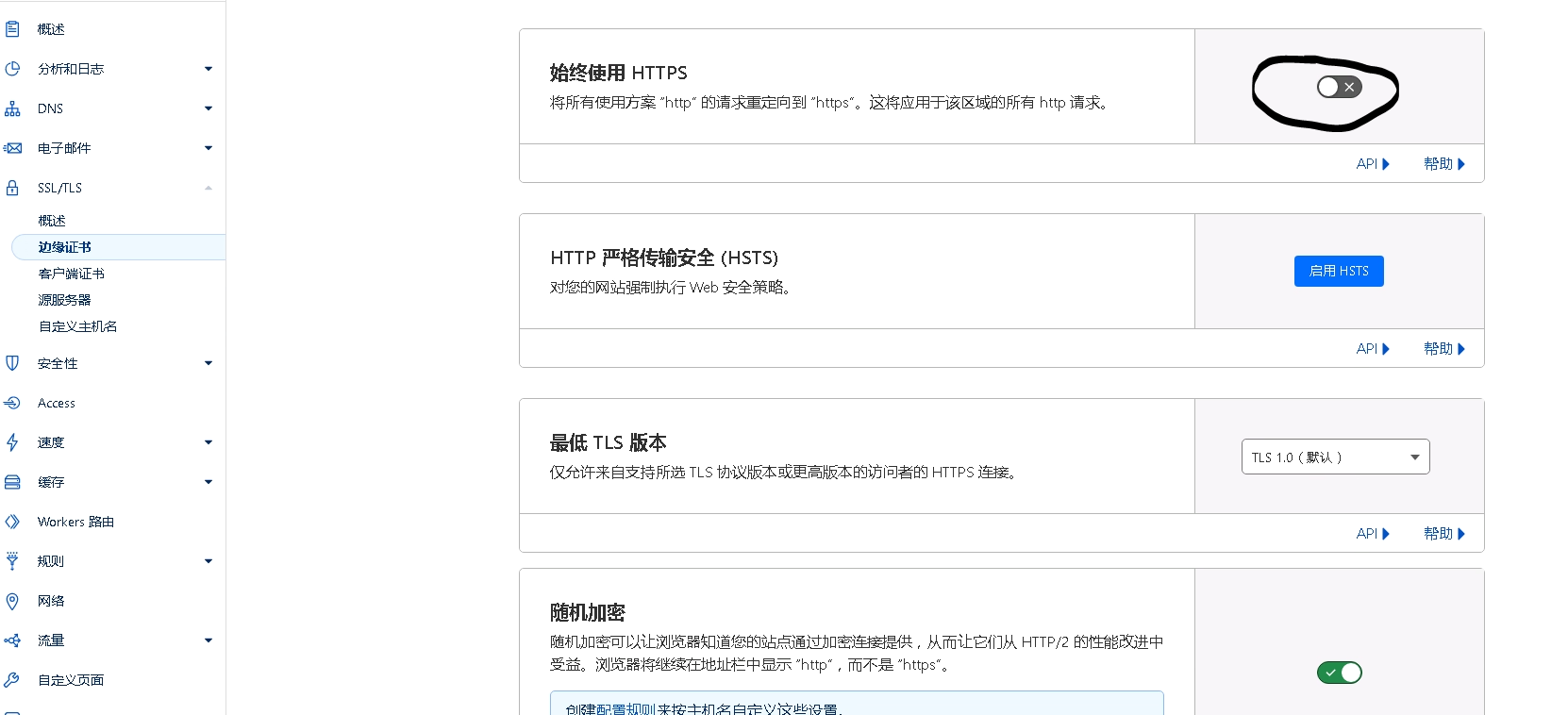
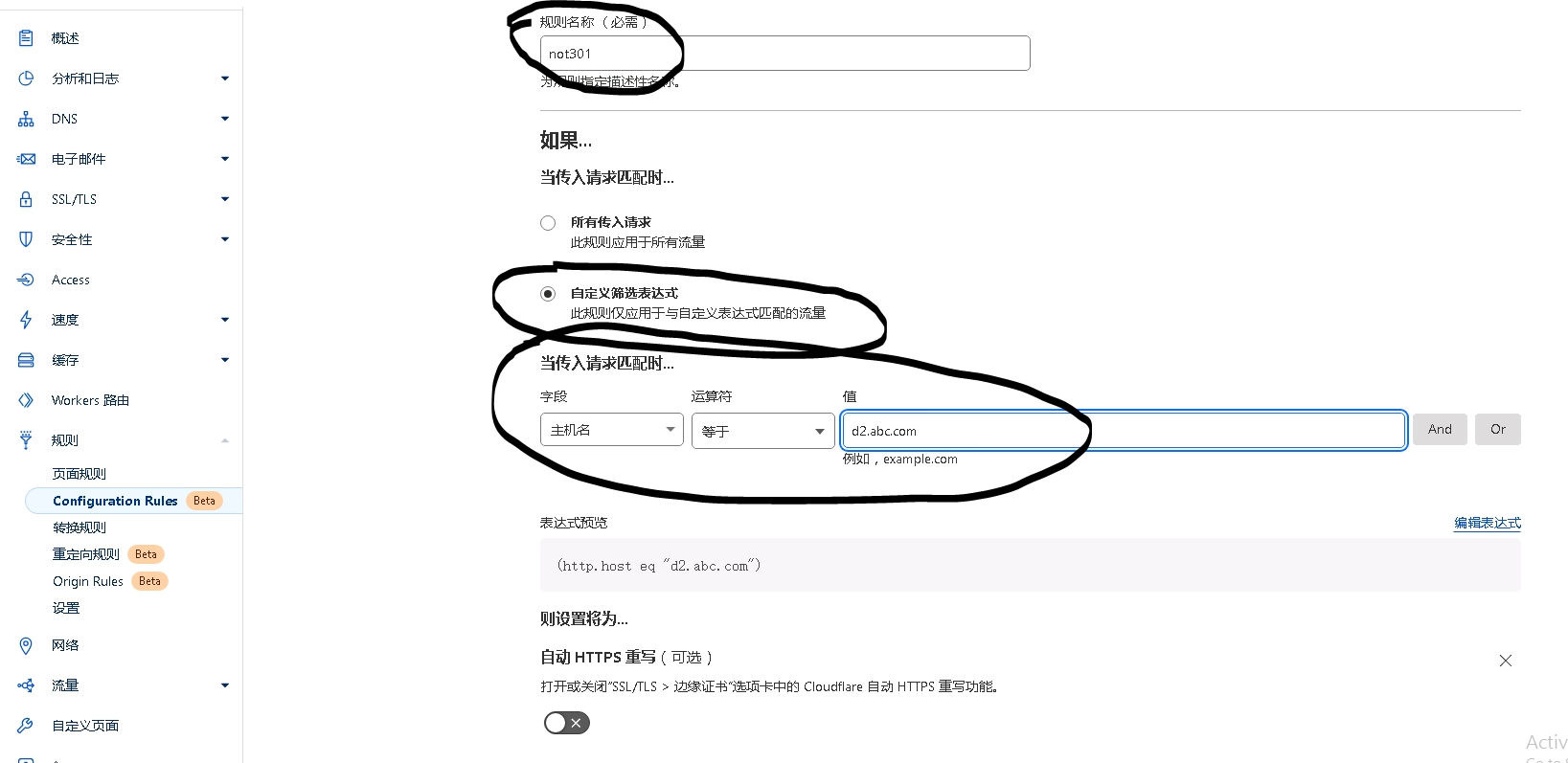
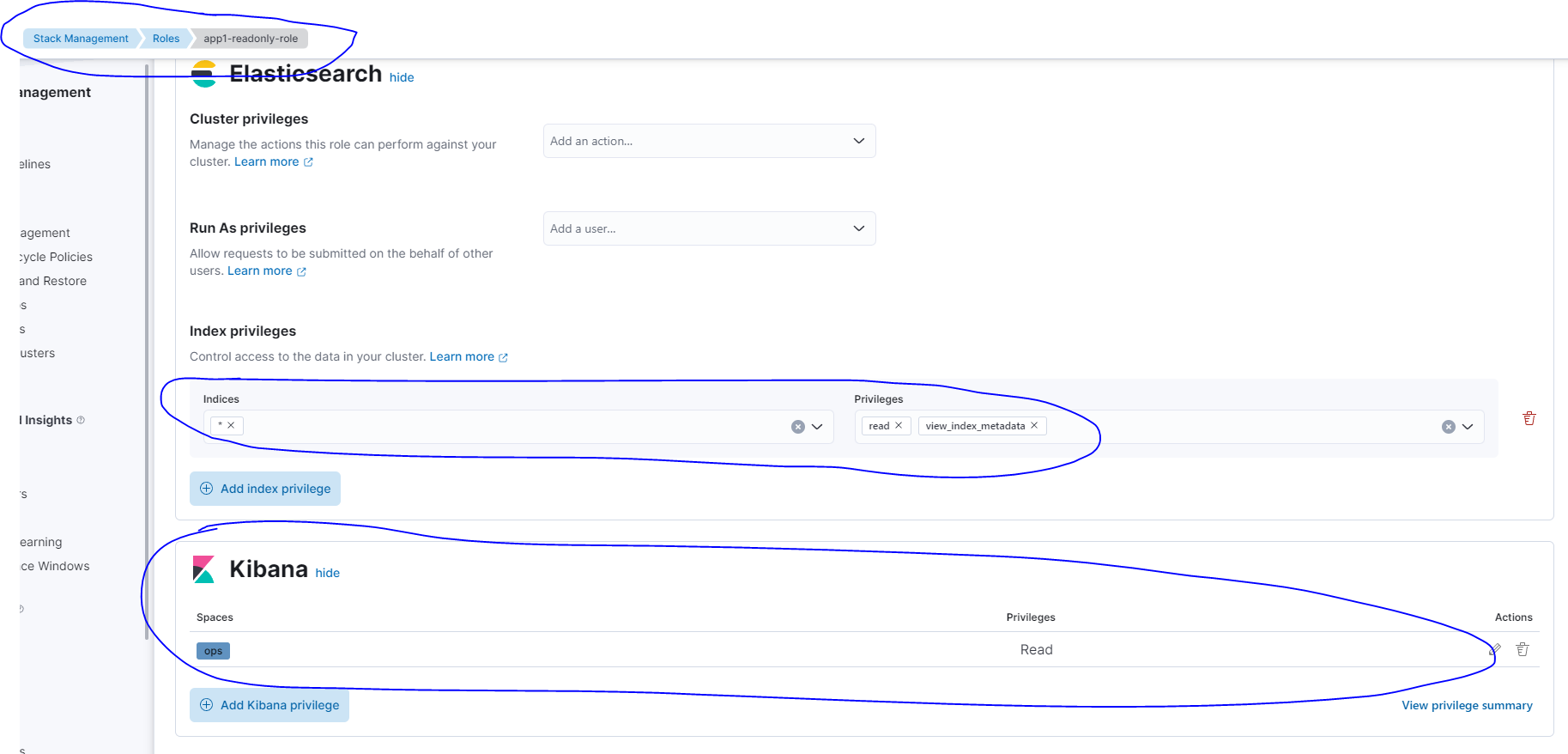
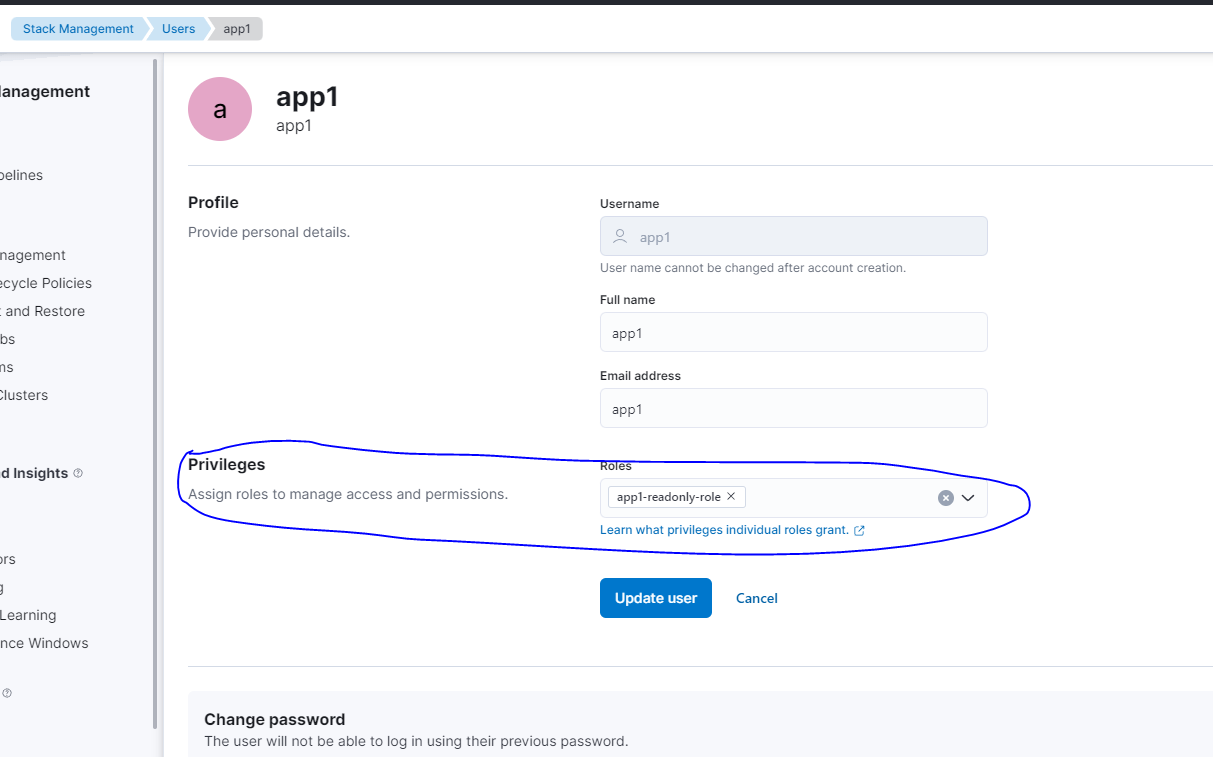
akamai cdn api 使用
Akamai CDN API 说明文档,调用 API 之前需要先根据官方文档说明 Create API Client
Python SDK 使用
根据官方文档说明安装 edgegrid-python,并配置 Create API Client Key 信息 [1]。
pip install edgegrid-python |
获取账号信息
大多数 API 使用都需要提供 groupId,accountId,contractIds,通过以下接口获取这些信息 [2]
>> import requests |
如果
Property中存在分组,每个分组都有一个独立的groupId