Encryption : 将 Plain Text 转换为 Ciphertext 的过程,通常使用一种加密算法(Encrypt Algorithm)
Decryption : 解密,将 Ciphertext 转换为 Plain Text 的过程,通常使用和加密算法(Encrypt Algorithm)相对应的解密算法(Decrypt Algorithms)
Cipher : 加密和解密过程中算法使用的密码。
Block Cipher : 在对数据进行加密之前,需要首先将其分割成块(Block)
Stream Cipher : 加密过程中无需将其分割成块(Block)
Key : 通常值密钥对(公钥/私钥)
以下是一些较为经典的加密算法
Algorithm
Description
AES Advanced Encryption Standard, also called Rijndael
- Symmetric Cryptography - Block Cipher 。encrypting data in 128-, 192-, 256-, 512- bit, blocks using a 128-, 192-, 256, or 512-bit key
Blowfish
- Symmetric Cryptography - Block Cipher 。encrypting data in 64-bit blocks using the same 32-bit to 448-bit keys for encrypting/decrypting.
CAST5
- Symmetric Cryptography - Block Cipher 。 encrypting data in 64-bit blocks using the same up to 128-bit key for encrypting/decrypting.
DES Data Encryption Standard
已经被认为是不安全的 - Symmetric Cryptography - Block Cipher 。encrypting data in 64-bit blocks using the same 56-bit key for encrypting/decrypting.
3DES
增强的 DES 加密算法 - Symmetric Cryptography Data is encrypted up to 48 times with three different 56-bit keys before the encryption process is completed.
IDEA
- Symmetric Cryptography - Block Cipher 。 encrypting data in 64-bit blocks using the same 128-bit key for encrypting/decrypting
RC5
- Symmetric Cryptography - Block Cipher 。 encrypting data in 32-, 64-``, or 128- bit blocks ,using the same up to 2,048-bit keys for encrypting/decrypting
RC6
- Symmetric Cryptography Same as RC5, but slightly faster
EI Gamal
- Asymmetric Cryptography Uses two keys derived from a logarithm algorithm
Elliptic Curve Cryptosystems
- Asymmetric Cryptography Uses two keys derived from an algorithm containing two randomly chosen points on an elliptic curve.
RC4 also called ArcFour or ARC4
- Stream Cipher encrypting data in 64-bit blocks using a variable key size for encrypting/decrypting.
Linux 审计系统提供了一种方式来跟踪系统上与安全相关的信息。根据预配置的规则,审计会生成日志条目,来尽可能多地记录系统上所发生的事件的相关信息。对于关键任务环境而言至关重要,可用来确定安全策略的违反者及其所执行的操作。审计不会为您的系统提供额外的安全,而是用于发现系统上使用的安全策略的违规。可以通过其他安全措施(如 SELinux)进一步防止这些违规。 [1]
# rpm -Va .......T. /usr/src/kernels/3.10.0-1160.114.2.el7.x86_64/virt/lib/Kconfig .......T. /usr/src/kernels/3.10.0-1160.114.2.el7.x86_64/virt/lib/Makefile S.5....T. c /root/.bash_profile S.5....T. c /root/.bashrc .M....... /var/run/supervisor missing /etc/filebeat/fields.yml SM5....T. c /etc/filebeat/filebeat.yml ....L.... c /etc/pam.d/fingerprint-auth ....L.... c /etc/pam.d/password-auth ....L.... c /etc/pam.d/postlogin ....L.... c /etc/pam.d/smartcard-auth ....L.... c /etc/pam.d/system-auth
# systemd-analyze critical-chain The time when unit became active or started is printed after the "@" character. The time the unit took to start is printed after the "+" character.
要查看 parted 常见用法,可以参考 parted --help 或在交互模式中使用 help 指令
查看分区表信息
要查看系统上的分区信息,使用以下方式之一
parted -l
# parted -l Model: Amazon Elastic Block Store (nvme) Disk /dev/nvme0n1: 85.9GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags:
Number Start End Size File system Name Flags 14 1049kB 5243kB 4194kB bios_grub 15 5243kB 116MB 111MB fat32 boot, esp 1 116MB 85.9GB 85.8GB ext4
Model: Amazon Elastic Block Store (nvme) Disk /dev/nvme1n1: 107GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags:
Number Start End Size Type File system Flags 1 1049kB 53.7GB 53.7GB primary ext4
Model: Unknown (unknown) Disk /dev/zram0: 33.2GB Sector size (logical/physical): 4096B/4096B Partition Table: loop Disk Flags:
Number Start End Size File system Flags 1 0.00B 33.2GB 33.2GB linux-swap(v1)
parted 交互模式,在交互模式中使用指令 p
# parted GNU Parted 3.4 Using /dev/nvme0n1 Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) p Model: Amazon Elastic Block Store (nvme) Disk /dev/nvme0n1: 85.9GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags:
Number Start End Size File system Name Flags 14 1049kB 5243kB 4194kB bios_grub 15 5243kB 116MB 111MB fat32 boot, esp 1 116MB 85.9GB 85.8GB ext4
(parted) mklabel gpt Warning: The existing disk label on /dev/nvme1n1 will be destroyed and all data on this disk will be lost. Do you want to continue? Yes/No? Yes (parted)
(parted) p Model: SanDisk Ultra (scsi) Disk /dev/nvme1n1: 123GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 123GB 123GB xfs alldisk
使用 quit 指令退出 parted 交互模式。
fdisk 交互模式中,只有最终执行了 w 命令保存,对硬盘的操作才会最终生效,和 fdisk 不同,parted 命令对硬盘的更改立即生效
在 Linux 中,命令提供的 man 手册是一份非常详细的命令使用说明手册,要了解命令的使用方法及其工作原理,熟练参考 man 手册是及其必要的。
man 手册中不仅包含了命令的使用方法,还包括了命令相关的 (配置)文件说明 、 System Calls 等相关信息,下表中列出了 man 手册不同编号对应的功能
Section Number
Section Name
Description
1
User Commands
用户可以在 shell 中运行的指令说明 man 命令不指定 Section Number 时默认为 1
2
System Calls
应用程序中的功能函数调用的内核函数
3
C Library Functions
应用程序针对特定的函数库提供的接口
4
Devices and Special Files
程序使用的硬件或软件
5
File Formats and Conventions
涉及的文件类型(如配置文件)及约定
6
Games
7
Miscellaneous
其他杂项,如 协议 、 文件系统 、 字符集 等
8
System Administration Tools and Daemons
需要 root 权限或其他管理员权限运行的命令
要查看命令 man 的某个部分,可以使用以下命令查看 passwd 命令的 File Formats and Conventions
man 5 passwd
环境信息 :
Centos 7
为源码编译安装的软件安装 man 手册
使用源码编译安装的软件默认是没有 man 手册的,使用 man 命令会报以下错误
$ man fswatch No manual entry for fswatch
要为源码编译安装的软件安装 man 手册,可以参考以下步骤,此处示例软件为 fswatch,软件编译安装到了 /usr/local/fswatch-1.17.1/
一般情况下,源码中会附带软件的使用文档,编译安装后,可能位于以下路径,fswatch 编译安装后的 man 手册位于 /usr/local/fswatch-1.17.1/share/man/man7/fswatch.7
ls /usr/local/fswatch-1.17.1/doc ls /usr/local/fswatch-1.17.1/share/doc ls /usr/local/fswatch-1.17.1/share/man/
man 命令使用的文档默认来源于 /usr/share/man/
$ ls /usr/share/man/ cs de fr hu it ko man1 man1x man2x man3p man4 man5 man6 man7 man8 man9 mann pl pt_BR ro sk tr zh_CN da es hr id ja man0p man1p man2 man3 man3x man4x man5x man6x man7x man8x man9x nl pt pt_PT ru sv zh zh_TW
要为编译安装软件的安装 man 帮助文档,首先将 fswatch 的帮助文档复制到 man 页面的目录
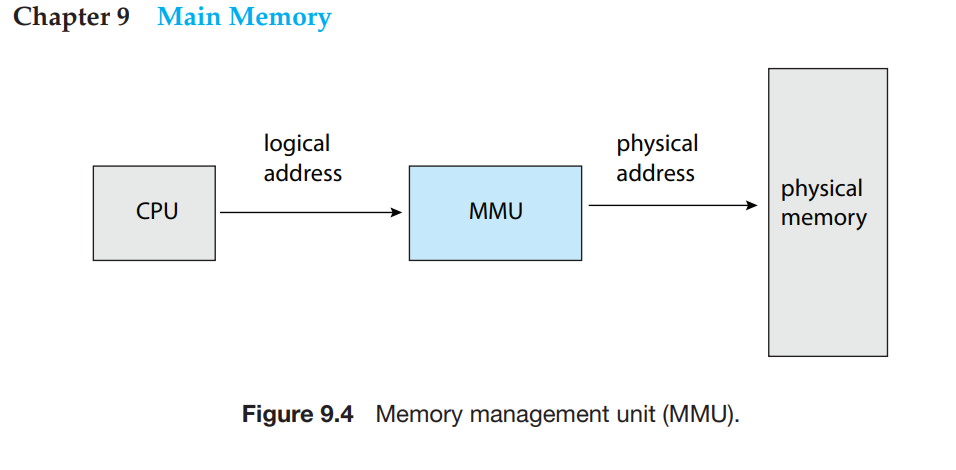
程序运行过程中,CPU 操作的是 Virtual Memory Address,需要由硬件设备 MMU(Memory Management Unit)负责将 Virtual Memory Address space 映射到对应的 Physical Memory Address space。程序或者是 CPU 运行过程中,不会直接操作(访问/access)物理内存地址空间。
DMA
Direct Memory Access (DMA) 在 CPU 需要从存储读写大量数据到内存时,如果数据通过 CPU 中转,成本太高,为了解决这个问题,DMA 被采用,在传输大块数据时,首先在 CPU 中为数据设置好必要的 buffer、指针、计数器等资源,设备控制器(DMA Controller)直接(在磁盘和内存中)传输数据块而无须 CPU 参与实际的数据传输,只需要在数据块传输完成时,向 CPU 产生中断以指示设备控制器(DMA Controller)数据传输已完成。在 DMA 过程中,CPU 依旧可以做其他工作。 [1]
DLLs(Dynamic Linked Libraries) 是在运行过程中,动态加载库文件。这个特性在系统库文件(如 standard C language library)中很常用。程序编译过程中及运行过程中动态加载系统库文件,无需将系统库文件打包进应用程序镜像中,应用程序运行过程中动态加载系统库文件,如果要加载的目标系统库文件已经存在于内存中,则无需重复加载,直接共享使用即可。DLLs 有以下优势:
Symmetric Multiprocessing (SMP),对称处理系统,在系统中存在多个处理器,每个处理器中包含一个或多个 CPU,每个 CPU 有自己的 L1 Cache (CPU 独享)和 Register,每个处理器有 L2 Cache(处理器中的多个 CPU 共享 L2 cache),同一个处理器中的 CPU 使用处理器内部通信系统通信,跨处理器的 CPU 之间通过系统总线(Bus)通信。 [2]
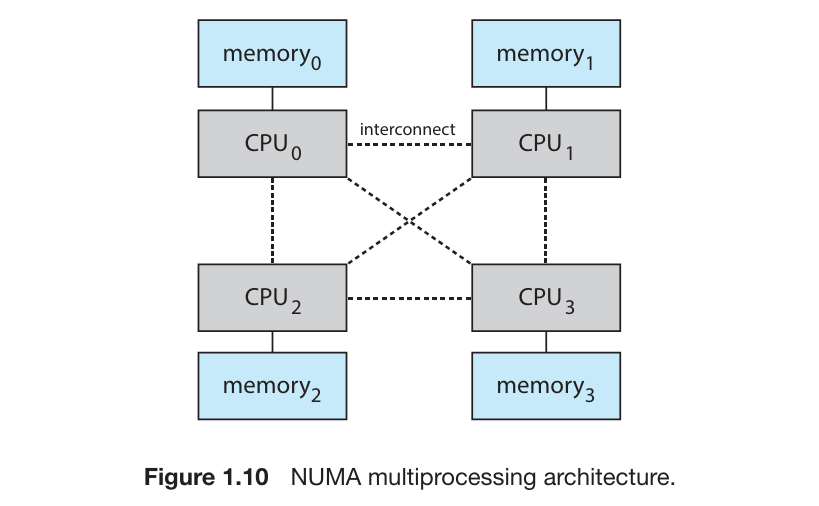
NUMA
系统中的处理器不宜太多,多处理器可以提高系统的任务处理能力,但是当 CPU 过高时,对系统总线的争抢会成为系统瓶颈。
为了避免太多 Processors 争抢系统总线造成的性能下降,一个可选的 方法是为每个 CPU(或 CPU 集)提供专用的本地内存,CPU 通过一个更小更快的本地 bus 连接专用的本地内存。所有的 CPU 通过一个 内部通信系统 进行连接,所有 CPU 共享同一个物理地址空间,这种架构被称为 Non-uniform Memory Access (NUMA)
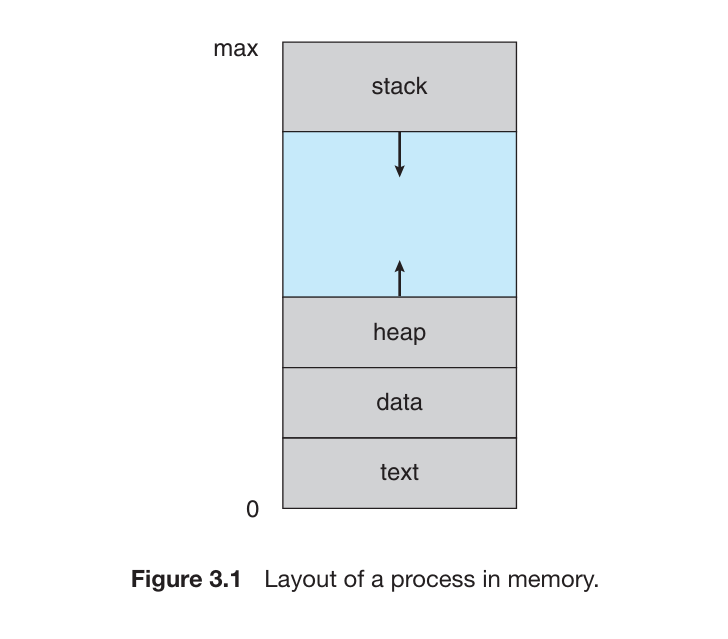
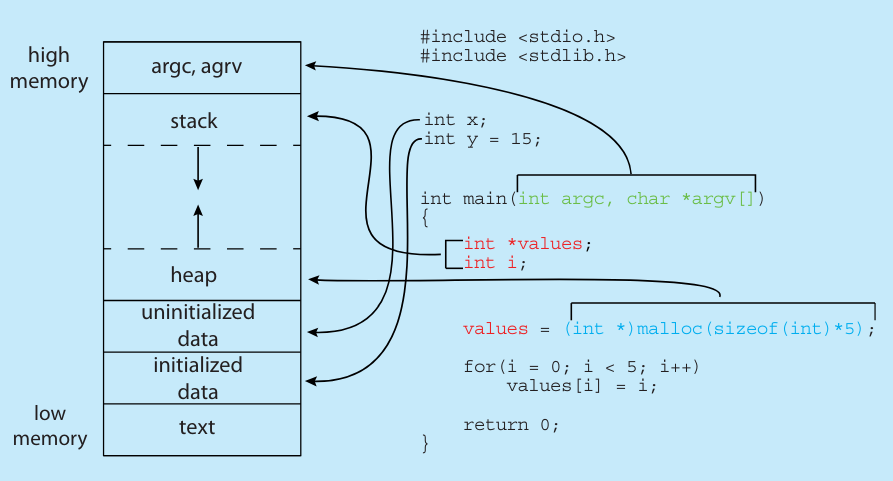
Program and Process
Program 是一个静态实体,只是存储在操作系统中的文件(集合)
Process 是操作系统上的活动(Active)实体,是 Program 由操作系统加载运行之后的实体。
Process 运行过程中需要操作系统为其分配各种资源,如 CPU、Memory、Files、IO 等来完成其运行。
如果一个 Program 被操作系统运行(启动)了多次,那么其产生的多个 Process 属于分割(单独)的实体。
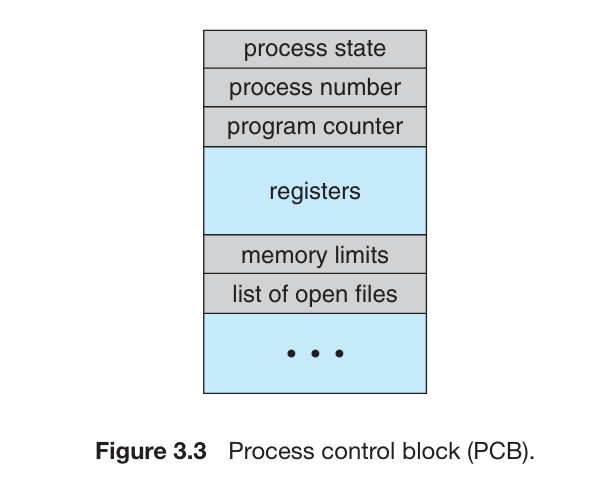
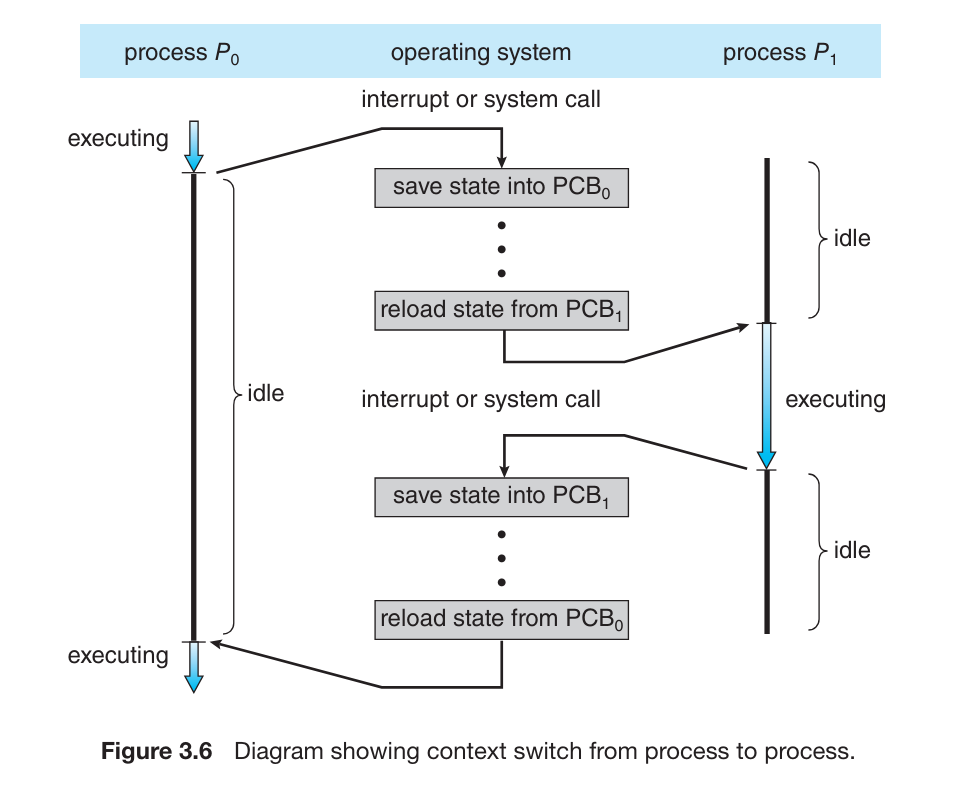
Process Control Block
PCB (Process Control Block) 代表了 OS 中进程(Process)的各种信息,包括
Process State : 进程当前的状态
Program counter : 程序计数器指针。指向了当前进程中下一个要执行的指令的地址。
CPU registers : 根据计算机架构的不同,可能包括计数器、栈指针(stack pointers)、通用指针(general-purpose registers)等。
CPU-scheduling information : 包括进程优先级(process priority)信息、调度队列指针(pointers to scheduling queues)以及其他调度参数等。
Memory-management information : 进程使用的内存信息
Accounting information : CPU 数量和 CPU 使用时间,CPU 使用限制,进程数量等信息
Processes 在指定的 CPU 上运行的过程中,一般会加载数据到 CPU 的 cache 中,下一次调度到同一个 CPU 运行时,仍然可以使用 Cache 中的数据(称为 warm cache)。 [5]
假如后续 CPU 调度时,此进程被调度到了另一个 CPU,那么原来 CPU Cache 中的数据就要失效,新的 CPU 必须从新加载数据到 Cache 中。因为让 CPU Cache 中的数据失效和加载 Memroy 中的数据到 Cache 中是一个成本较高的操作,现代的 SMP 操作系统都会避免这类缓存迁移操作,会尽量将进程调度到同一个 CPU 以使用 warm cache 数据,这就是 Processor Affinity,一个进程对其正在运行的 CPU 拥有亲和性。
常见的 CPU 亲和性(Processor Affinity)有两类:
soft affinity : 尽量保证一个进程被调度到同一个 CPU,但是不保证一定,尽最大可能
hard affinity : 允许配置进程只运行在选定的 CPU 集(subset of processors)
服务器上电运行后启动的第一个程序是 bootstrap loader program (操作系统启动引导程序,如 Linux 中的 grub2,其启动之后会加载操作系统)。RAM 是易失性存储,不能将 bootstrap program 放置到 RAM 中,当下主机会使用 EEPROM 放置 bootstrap program。bootstrap program 可以被修改,但是不能频繁修改,它属于慢速存储,其中包含了不经常会使用的静态程序和数据。比如 iPhone 使用了 EEPROM 存储了设备 serial numbers 和 hardware information
GNU: GNU’s Not Unix,Richard Stallman 于 1984 年开始开发的自由(free)的类 Unix 操作系统。包括编译器、编辑器、库文件、游戏等应用,没有内核。
GNU/Linux: 1991 年,Linus Torvalds 发布了最初版类 Unix 操作系统内核,并使用了 GNU 提供的编译器和工具。
FSF: Free Software Foundation,自由软件基金会,由 Richard Stallman 于 1985 年成立,旨在鼓励和推动自由软件的使用和开发。自由不等于免费
GPL: GNU General Public License。
ELF: Executable and Linkable Format.
ABI : Application Binary Interface. ABI 定义了在不同架构以及不同的操作系统中,一个二进制代码(Binary Code)提供的接口的差异性。ABI 定义了二进制代码的底层细节,如地址宽度、向系统调用(system calls)提供参数的方法、运行时的堆栈(stack)的组织方式、系统库的二进制格式、数据类型等信息。ABI 是架构级别(architecture-level)的定义,如果一个二进制文件是根据特点的架构(如 ARMv8 processor)编译(链接)而成,那将他迁移到支持此 ABI 的另外的系统上,理论上它也可以正常运行。[3]
RTE : Run Time Environment.
LKMs : Loadable Kernel Modules.
Darwin : iOS/MacOS 底层的类 Unix 操作系统,主要基于 BSD UNIX 的 microkernel
CMT : Chip MultiThreading. 一个物理 CPU 核上实现了双线程或多线程的支持。在一个 CPU 线程因等待内存加载数据而空闲(Memory Stall)时,另一个 CPU 线程开始执行。每个 CPU 线程拥有自己独立的状态数据(architectural state)、指令指针(instruction pointer)、注册器(regester set)等,可以将其当作一个单独的逻辑 CPU 来运行单独的线程(进程/Job)。如 Intel 的超线程(hyper-threading)或者叫 SMT(Simultaneous Multi-Threading)
CFS : Completely Fail Scheduler。Linux kernel 2.6.23 版本开始默认的 CPU 调度算法。