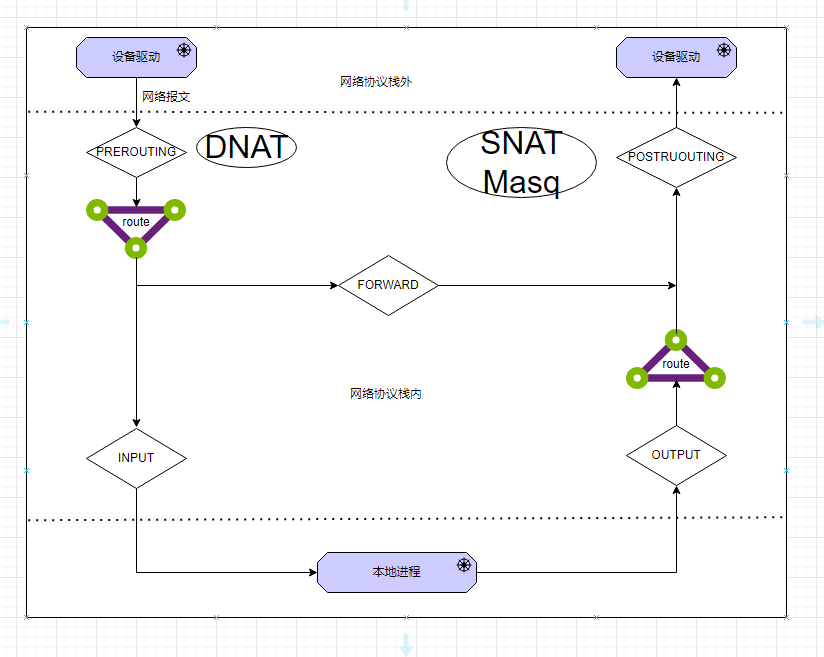
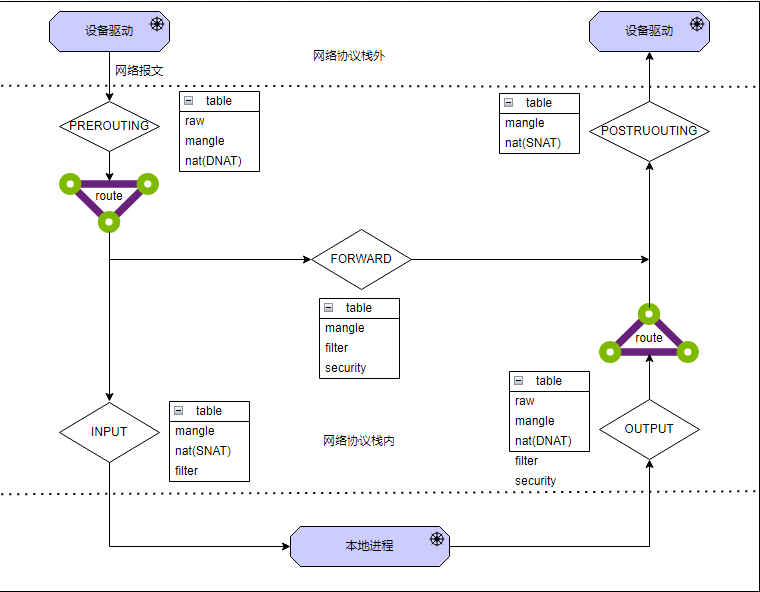
$ ln -s /proc/84040/ns/net /var/run/netns/84040 $ ip netns ls 84040 (id: 0)
通过 network namespace 名称(此处为 84040)配置容器中网卡的 IP 地址信息
ip netns exec 84040 ip link set dev veth0_p name eth0 ip netns exec 84040 ip link set dev eth0 up
ip netns exec 84040 ip add add 172.17.0.10/16 dev eth0
ip netns exec 84040 ip route add default via 172.17.0.1
进入容器检查网络信息
$ ip add 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 15: eth0@if16: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 7e:36:b3:20:a1:8c brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.10/16 scope global eth0 valid_lft forever preferred_lft forever $ ip route show default via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.10
进入容器测试网络连接
$ ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=127 time=37.4 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=127 time=37.0 ms ^C --- 8.8.8.8 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1000ms rtt min/avg/max/mdev = 37.047/37.234/37.422/0.269 ms
certificate verify failed: unable to get local issuer certificate
报错信息如下:
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1007) ... urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1007)>
# pip install --upgrade pip Requirement already satisfied: pip in /usr/local/lib/python3.9/site-packages (23.0.1) Collecting pip Downloading pip-23.2.1-py3-none-any.whl (2.1 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/2.1 MB ? eta -:--:--ERROR: Exception: Traceback (most recent call last): File "/usr/local/lib/python3.9/site-packages/pip/_internal/cli/base_command.py", line 160, in exc_logging_wrapper status = run_func(*args) File "/usr/local/lib/python3.9/site-packages/pip/_internal/cli/req_command.py", line 247, in wrapper return func(self, options, args) ... File "/usr/local/lib/python3.9/site-packages/pip/_internal/operations/prepare.py", line 107, in get_http_url from_path, content_type = download(link, temp_dir.path) File "/usr/local/lib/python3.9/site-packages/pip/_internal/network/download.py", line 147, in __call__ for chunk in chunks: File "/usr/local/lib/python3.9/site-packages/pip/_internal/cli/progress_bars.py", line 52, in _rich_progress_bar with progress: File "/usr/local/lib/python3.9/site-packages/pip/_vendor/rich/progress.py", line 1169, in __enter__ self.start() File "/usr/local/lib/python3.9/site-packages/pip/_vendor/rich/progress.py", line 1160, in start self.live.start(refresh=True) File "/usr/local/lib/python3.9/site-packages/pip/_vendor/rich/live.py", line 132, in start self._refresh_thread.start() File "/usr/local/lib/python3.9/threading.py", line 899, in start _start_new_thread(self._bootstrap, ()) RuntimeError: can't start new thread
[notice] A new release of pip is available: 23.0.1 -> 23.2.1 [notice] To update, run: pip install --upgrade pip
>>> help(requests.get) get(url, params=None, **kwargs) Sends a GET request. :param url: URL for the new :class:`Request` object. :param params: (optional) Dictionary, list of tuples orbytes to send in the query string for the :class:`Request`. :param \*\*kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response
def read_large_file(file_path): """ Generator function to read a large file line by line. """ with open(file_path, 'r') as file: for line in file: yield line
使用以下方法使用大文本中的数据
next 方法。调用生成器函数(read_large_file),会返回一个 Generator 对象,通过 next() 方法会迭代调用生成器的下一个值(yield 表达式的值)
file_path = 'large_file.txt' # next 方法: 首先 line = read_large_file(file_path)
next(line) # 返回第一行 next(line) # 返回第二行,以此类推可以读取所有行
for 循环。调用生成器函数返回一个生成器对象,这个对象实现了迭代器协议。
def read_large_file(file_path): """ Generator function to read a large file line by line. """ with open(file_path, 'r') as file: for line in file: yield line # Usage example file_path = 'large_file.txt' for line in read_large_file(file_path): print(line.strip())
分批读取大文件中的数据
在处理大文件的过程中,如果需要批量多行读取文件内容,参考以下代码
def read_file_in_chunks(file_path, chunk_size=1024): """ Generator function to read a file in chunks. """ with open(file_path, 'r') as file: while True: chunk = file.readlines(chunk_size) if not chunk: break for line in chunk: yield line # Usage example file_path = 'large_file.txt' for line in read_file_in_chunks(file_path): print(line.strip())